Windows自身没有提供类似Linux cgroup的能力来限制进程或进程组的资源占用,进程CPU/IO/内存/网络等资源的控制只能由自己实现。目前已有第三方的实现,主要是限制进程CPU的占用,如文档 < 21 Best Ways to Limit the CPU Usage of a Process > 所描述的BES,Process Tamer等软件。自Windows 8及Server 2012开始Windows系统有提供以job为单位的CPU占用及内存上限设置,之前的版本则只能以进程或线程为单位进行限制。
进程CPU占用限制方案
即时轮询系统所有进程(线程)的CPU占用,当发现所设定进程有超标时强制暂停进程所有线程的执行,然后在适当的时机再恢复执行。其中所涉及技术点:
进程CPU占用查询 GetProcessTimes
BOOL GetProcessTimes(
[in] HANDLE hProcess,
[out] LPFILETIME lpCreationTime,
[out] LPFILETIME lpExitTime,
[out] LPFILETIME lpKernelTime,
[out] LPFILETIME lpUserTime
);此函数可以获取进程从创建至当前的总运行时间及总的CPU时间,(KernelTime + UserTime) < 系统CPU数 * (当前时间 - CreationTime)
线程CPU占用查询 GetThreadTimes
BOOL GetThreadTimes(
[in] HANDLE hThread,
[out] LPFILETIME lpCreationTime,
[out] LPFILETIME lpExitTime,
[out] LPFILETIME lpKernelTime,
[out] LPFILETIME lpUserTime
);QueryThreadCycleTime可以提供更精准的CPU时间数据,单位为CPU时钟周期
BOOL QueryThreadCycleTime(
[in] HANDLE ThreadHandle,
[out] PULONG64 CycleTime
);线程暂停及恢复
Windows平台没有提供暂停整个进程的支持函数,只能以线程为单位来操作,即SuspendThread及ResumeThread:
DWORD SuspendThread(
[in] HANDLE hThread
);
DWORD ResumeThread(
[in] HANDLE hThread
);CPU亲和性设置: SetProcessAffinityMask
BOOL SetProcessAffinityMask(
[in] HANDLE hProcess,
[in] DWORD_PTR dwProcessAffinityMask
);此函数可以限定进程及其所有线程所能使用的CPU,故一定程序上亦限定了进程最大的系统CPU占用率。
DWORD_PTR SetThreadAffinityMask(
[in] HANDLE hThread,
[in] DWORD_PTR dwThreadAffinityMask
);此函数可单独限制特定线程的CPU亲和性。
进程优先级设置: SetPriorityClass
优先级解决的是优先运行及退让CPU的问题,本质上并不能限定CPU占用,只是优先级高于当前任务的忙碌的时候,当前进程会主动退让CPU 线程优先级设置:SetThreadPriority
BOOL SetThreadPriority(
[in] HANDLE hThread,
[in] int nPriority
);Job Objects
Windows系统提供了Job的概念用以管理多个进程,可以限制Job对象内所有进程及期线程的CPU核心占用、CPU占用及内存分配上限等,均通过SetInformationJobObject来实现,具体的CPU限制由JOBOBJECT_CPU_RATE_CONTROL_INFORMATION管理,内存限制则由JOBOBJECT_EXTENDED_LIMIT_INFORMATION来管理。
BOOL SetInformationJobObject(
[in] HANDLE hJob,
[in] JOBOBJECTINFOCLASS JobObjectInformationClass,
[in] LPVOID lpJobObjectInformation,
[in] DWORD cbJobObjectInformationLength
);需要注意的是CPU占用设置只有Windows 8及Server 2012之后的版本有效。
CPU Sets
此部分只限定了CPU Affinity属性
实验验证
可以直接利用开源项目go-winjob验证,验证系统Windows 8 x64,go-winjob git repo: https://github.com/kolesnikovae/go-winjob
验证程序
#include <stdio.h>
#include <stdlib.h>
void main(int argc, char *argv[])
{
unsigned long total = 0, count = 0, i = 0;
while (1) {
if (malloc(1024)) {
total += 1024;
count++;
}
if (!(++i & 4095))
printf("alloc: %u size: %u bytes\n", count, total);
}
}无限制
在无限制的情况下,此进程会占满一个CPU核心,commit内存总占用达2G
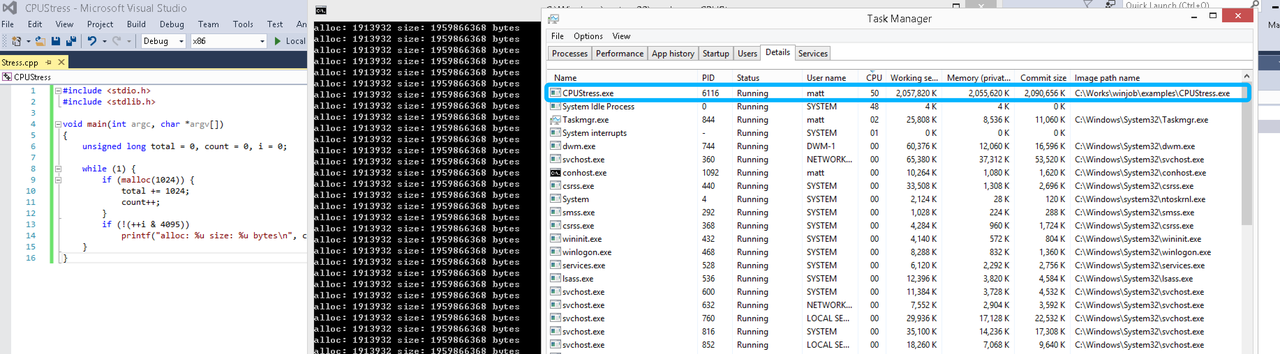
单一进程
在设定CPU上限16%及内存16M上限之后,结果如下:
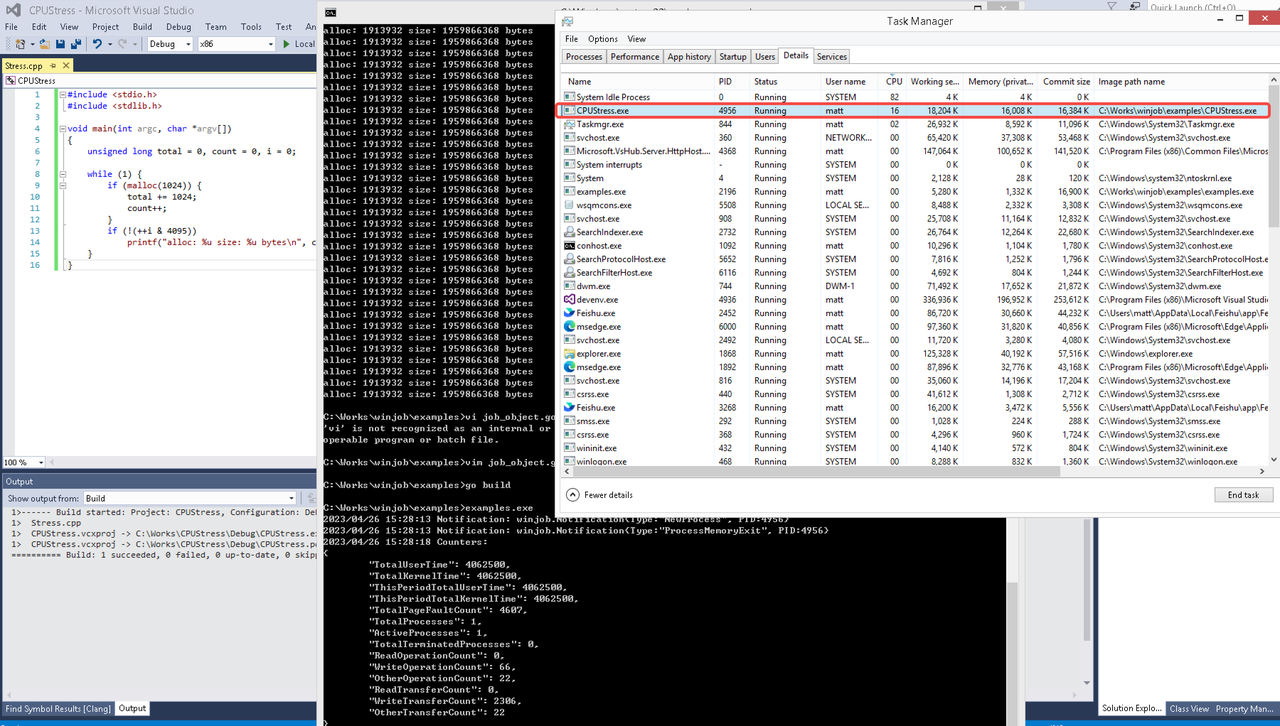 examples/job_object.go按如下修改:
examples/job_object.go按如下修改:
var limits = []winjob.Limit{
winjob.WithBreakawayOK(),
winjob.WithKillOnJobClose(),
winjob.WithActiveProcessLimit(3),
winjob.WithProcessTimeLimit(10 * time.Second),
winjob.WithCPUHardCapLimit(1600), // 16%
winjob.WithProcessMemoryLimit(16 << 20), // 16MB
winjob.WithWriteClipboardLimit(),
}
const defaultCommand = ".\\CPUStress.exe"多进程(双进程)
将winjob.WithProcessMemoryLimit 改为 winjob.WithJobMemoryLimit,后者表示此job内所有进程要占用的总内存限制:
var limits = []winjob.Limit{
winjob.WithBreakawayOK(),
winjob.WithKillOnJobClose(),
winjob.WithActiveProcessLimit(3),
winjob.WithProcessTimeLimit(10 * time.Second),
winjob.WithCPUHardCapLimit(1600), // 16%
winjob.WithJobMemoryLimit(16 << 20), // 16MB
winjob.WithWriteClipboardLimit(),
}验证结果如下:
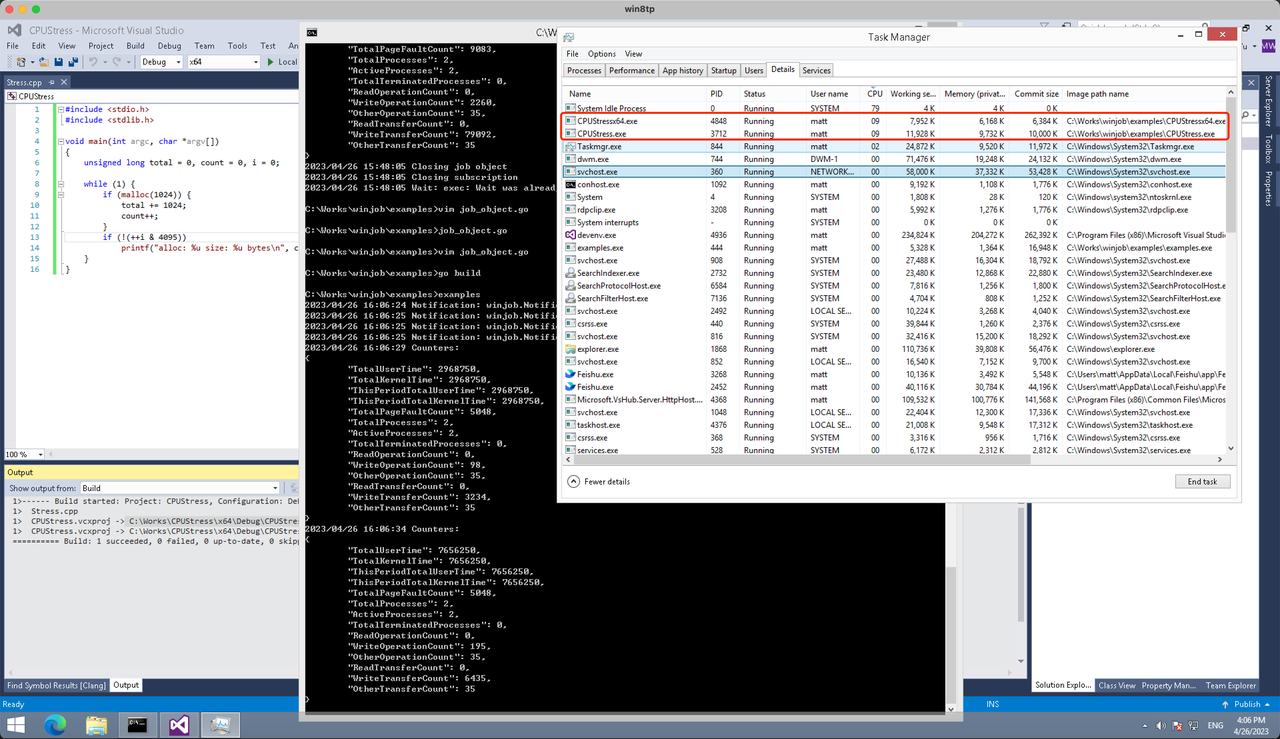
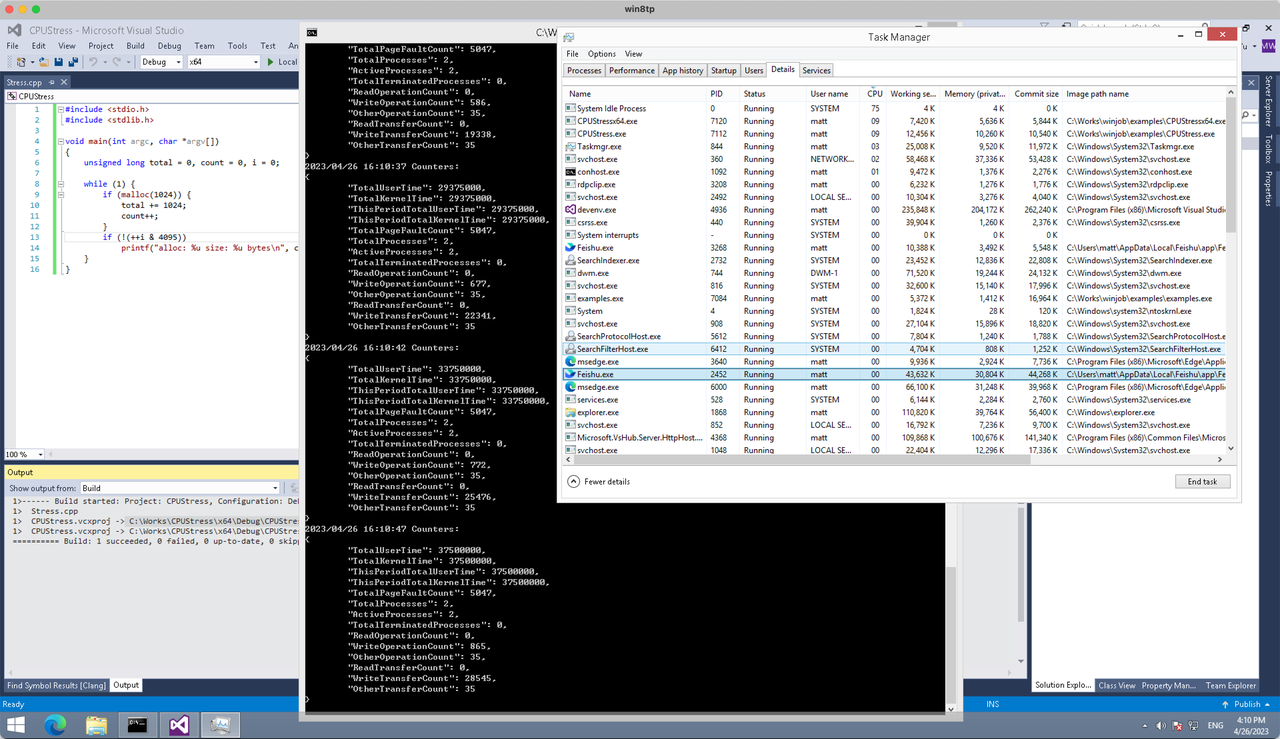
winjob example代码:
// +build windows
package main
import (
"encoding/json"
"log"
"os"
"os/exec"
"os/signal"
"time"
"golang.org/x/sys/windows"
"github.com/kolesnikovae/go-winjob"
)
var limits = []winjob.Limit{
winjob.WithBreakawayOK(),
winjob.WithKillOnJobClose(),
winjob.WithActiveProcessLimit(3),
winjob.WithProcessTimeLimit(10 * time.Second),
winjob.WithCPUHardCapLimit(1600), // 16%
winjob.WithJobMemoryLimit(16 << 20), // 16MB
winjob.WithWriteClipboardLimit(),
}
const defaultCommand = ".\\CPUStress.exe"
const stressCommand = ".\\CPUStressX64.exe"
func main() {
job, err := winjob.Create("", limits...)
if err != nil {
log.Fatalf("Create: %v", err)
}
cmd := exec.Command(defaultCommand)
cmd.Stderr = os.Stderr
cmd.SysProcAttr = &windows.SysProcAttr{
CreationFlags: windows.CREATE_SUSPENDED,
}
if err := cmd.Start(); err != nil {
log.Fatalf("Start: %v", err)
}
stress := exec.Command(stressCommand)
stress.Stderr = os.Stderr
stress.SysProcAttr = &windows.SysProcAttr{
CreationFlags: windows.CREATE_SUSPENDED,
}
if err := stress.Start(); err != nil {
log.Fatalf("Start: %v", err)
}
s := make(chan os.Signal, 1)
signal.Notify(s, os.Interrupt)
c := make(chan winjob.Notification)
subscription, err := winjob.Notify(c, job)
if err != nil {
log.Fatalf("Notify: %v", err)
}
done := make(chan struct{})
go func() {
defer close(done)
ticker := time.NewTicker(time.Second * 5)
defer ticker.Stop()
var counters winjob.Counters
for {
select {
case <-s:
log.Println("Closing job object")
if err := job.Close(); err != nil {
log.Fatal(err)
}
log.Println("Closing subscription")
if err := subscription.Close(); err != nil {
log.Fatal(err)
}
return
case n, ok := <-c:
if ok {
log.Printf("Notification: %#v\n", n)
} else if err := subscription.Err(); err != nil {
log.Fatalf("Subscription: %v", err)
}
case <-ticker.C:
if err := job.QueryCounters(&counters); err != nil {
log.Fatalf("QueryCounters: %v", err)
}
b, err := json.MarshalIndent(counters, "", "\t")
if err != nil {
log.Fatal(err)
}
log.Printf("Counters: \n%s\n", b)
}
}
}()
if err := job.Assign(cmd.Process); err != nil {
log.Fatalf("Assign: %v", err)
}
if err := winjob.Resume(cmd); err != nil {
log.Fatalf("Resume: %v", err)
}
if err := job.Assign(stress.Process); err != nil {
log.Fatalf("Assign: %v", err)
}
if err := winjob.Resume(stress); err != nil {
log.Fatalf("Resume: %v", err)
}
if err := cmd.Wait(); err != nil {
log.Fatalf("Wait: %v", err)
}
if err := stress.Wait(); err != nil {
log.Fatalf("Wait: %v", err)
}
// Wait for a signal.
<-done
}


 直接映射方式其实是组相联映射的一种特例,亦称作是单路组相联。
直接映射方式其实是组相联映射的一种特例,亦称作是单路组相联。
 L2及LLC,以及早期的CPU的L1均是使用PIPT的方式,这是因为内存的物理地址是唯一的,这就大大简单化PIPT的实现逻辑。
L2及LLC,以及早期的CPU的L1均是使用PIPT的方式,这是因为内存的物理地址是唯一的,这就大大简单化PIPT的实现逻辑。







 可以看到整个曲线有4个平台,分别表示L1D、L2、LLC和内存。L1D的大小为32K,L2为256K,这部分和CPUZ的输出是一致的。
但第三个平台包含了512K、1M及2M,从4M开始延进有明显的跃升,从8M之后基本稳定在高位。这里就涉及到了LLC组织的不同:L1D及L2 Cache都是与物理核(Core)绑定的,而LLC是绑定CPU的,即2核的CPU的两个核心会共享同一个LLC,整个LLC是平均分配给每个核的,然后每个核心的LLC通过Ring Bus互联,即每个核又可以访问所有的LLC。这里在4M的stride发生波动的原因有两个:
可以看到整个曲线有4个平台,分别表示L1D、L2、LLC和内存。L1D的大小为32K,L2为256K,这部分和CPUZ的输出是一致的。
但第三个平台包含了512K、1M及2M,从4M开始延进有明显的跃升,从8M之后基本稳定在高位。这里就涉及到了LLC组织的不同:L1D及L2 Cache都是与物理核(Core)绑定的,而LLC是绑定CPU的,即2核的CPU的两个核心会共享同一个LLC,整个LLC是平均分配给每个核的,然后每个核心的LLC通过Ring Bus互联,即每个核又可以访问所有的LLC。这里在4M的stride发生波动的原因有两个: